




بهترین مدلهای زبان بزرگ (LLM)
مدلهای زبان بزرگ (LLM) نوع اصلی هوش مصنوعیهای پردازش متن هستند و اکنون تقریباً همهجا حضور دارند.
چتجیپیتی (ChatGPT) شناختهشدهترین ابزاری است که بهطور عمومی از یک مدل زبان بزرگ استفاده میکند، اما گوگل نیز از این مدلها برای تولید پاسخهای هوش مصنوعی در جستجو استفاده میکند و اپل نیز اواخر سال گذشته «هوش اپل» را که مبتنی بر مدل زبان بزرگ است، در دستگاههای خود عرضه کرد. و این تازه پیش از در نظر گرفتن سایر چتباتها، تولیدکنندههای متن و ابزارهای دیگری است که روی مدلهای زبان بزرگ ساخته شدهاند. مدلهای زبان بزرگ از اواخر دهه ۲۰۱۰ در آزمایشگاههای تحقیقاتی مورد مطالعه قرار گرفتهاند، اما پس از عرضه ChatGPT (که قدرت GPT را به نمایش گذاشت) این مدلها از آزمایشگاه بیرون آمدند و وارد دنیای واقعی شدند.
ما اکنون وارد نسلهای پنجم و ششم مدلهای زبان بزرگ شدهایم و با این پیشرفت، این مدلها روزبهروز کاربردیتر و قدرتمندتر میشوند. بزرگترین تغییر سال گذشته، مدلهای استدلالی بودند که برای حل مسائل پیچیده زمان بیشتری صرف میکنند. پیش از آن، معرفی مدلهای بزرگ چندرسانهای (LMM) بود که قادر به پردازش ورودیها و خروجیهای مختلفی مانند تصویر، صدا و ویدیو بهعلاوه متن هستند. البته سرعت بالای این پیشرفتها اوضاع را پیچیدهتر میکند. بنابراین در اینجا، برخی از مهمترین مدلهای LLM، LMM و مدلهای استدلالی را که اکنون در دسترس هستند بررسی خواهم کرد.
صدها مدل بزرگ زبان وجود دارد که برخی از آنها به دلایل مختلف اهمیت دارند. ذکر همه آنها تقریباً غیرممکن است و در هر صورت، به دلیل سرعت توسعه، این فهرست خیلی زود قدیمی خواهد شد.
(من این فهرست را برای اولین بار طی چند ماه اخیر بهروزرسانی کردهام و مدلهای جدید زیادی برای معرفی وجود دارد.)
کلمه «بهترین» را اینجا با کمی احتیاط بگیرید: من سعی کردهام با ارائه فهرستی از مهمترین، جالبترین و محبوبترین مدلها، دامنه را محدود کنم، نه الزاماً مدلهایی که در معیارهای سنجش بهترین عملکرد را دارند (هرچند بیشتر این مدلها عملکرد خوبی دارند). همچنین تمرکز من بیشتر روی مدلهای LLM، LMM و مدلهای استدلالی بوده که شما واقعاً میتوانید از آنها استفاده کنید، نه فقط مدلهایی که موضوع مقالات تحقیقاتی جالب هستند یا در تبلیغات مطرح شدهاند، چون ما اینجا بیشتر به جنبههای عملی علاقهمندیم.
مدل زبان بزرگ (LLM) چیست؟
مدل زبان بزرگ یا LLM، یک هوش مصنوعی تولیدکننده متن با کاربرد عمومی است. این مدل پشت صحنه همه چتباتهای هوش مصنوعی، تولیدکنندههای متن هوش مصنوعی و بیشتر ویژگیهای مبتنی بر هوش مصنوعی مثل پاسخهای خلاصهشده در جستجو قرار دارد.
اگر رابطهای کاربری پیچیده و روشهای جانبی را کنار بگذاریم، LLM ها یک ورودی (پرسش یا فرمان) دریافت کرده و یک پاسخ تولید میکنند. چتباتهایی که روی این مدلها ساخته شدهاند، صرفاً دنبال کلیدواژه نیستند تا پاسخهای از پیش تعیینشده بدهند، بلکه تلاش میکنند مفهوم پرسش را درک کنند و پاسخ مناسبی ارائه دهند.
به همین دلیل است که LLMها به سرعت محبوب شدند: همان مدلها (با یا بدون کمی آموزش اضافی) میتوانند به سوالات مشتریان پاسخ دهند، متون بازاریابی بنویسند، صورتجلسات را خلاصه کنند و کارهای بسیار دیگری انجام دهند.
اما LLMها فقط با متن کار میکنند، به همین دلیل مدلهای چندرسانهای بزرگ (LMM) روز به روز محبوبتر میشوند؛ چرا که قادرند تصاویر، یادداشتهای دستنویس، صدا، ویدیو و موارد دیگر را نیز پردازش کنند. بسیاری از بزرگترین مدلها اکنون LMM هستند.
مدل زبان بزرگ متنباز (Open Source LLM) چیست؟
سه دسته اصلی مدلهای زبان بزرگ وجود دارد: مدلهای مالکیتی (Proprietary)، باز (Open)، و متنباز (Open Source).
مدلهای مالکیتی مثل GPT-4o و Claude 4 از محبوبترین و قدرتمندترین مدلها هستند که توسط شرکتهای خصوصی توسعه و مدیریت میشوند. کد منبع، استراتژیهای آموزش، وزنهای مدل و حتی جزئیاتی مثل تعداد پارامترهای آنها محرمانه است. تنها راه دسترسی به این مدلها استفاده از چتباتها یا اپلیکیشنهایی است که بر پایه آنها ساخته شدهاند، یا از طریق API. نمیتوانید GPT-4o را روی سرور شخصی خود اجرا کنید.
مدلهای باز و متنباز بیشتر در دسترس هستند. شما میتوانید مدلهایی مثل Llama 3، Gemma 2 و DeepSeek R1 را از پلتفرمهایی مانند Hugging Face دانلود و روی دستگاههای خود اجرا کنید—و حتی آنها را با دادههای خود دوباره آموزش دهید تا مدل شخصی خود را بسازید. توسعهدهندگان میتوانند روی آنها چتباتها و اپلیکیشنهای خود را بسازند و حتی به جزئیاتی مانند وزن مدل و معماری سیستم برای درک نحوه عملکرد آنها دسترسی داشته باشند (تا حد ممکن).
اما تفاوت بین «باز» و «متنباز» چیست؟ شرکتهایی مثل Meta و Google ادعا میکنند Llama 3 و Gemma 2 باز (Open) هستند، طوری که انگار با متنباز یکی است، اما تفاوت مهمی وجود دارد.
مجوزهای متنباز بسیار آزاد هستند. معمولاً شما باید قبول کنید هر چیزی که با آن میسازید هم متنباز باشد و به توسعهدهندگان اصلی اعتبار دهید. اگر بخواهید با نرمافزار متنباز یک شرکت چند میلیارد دلاری بسازید یا حتی یک چتبات جنایی بسازید که به مردم آموزش دزدی بدهد، کاملاً آزاد هستید. پلیس ممکن است با پروژه دوم مشکل داشته باشد، اما شما هیچ مجوز نرمافزاری را نقض نکردهاید.
مجوزهای باز (Open) نیز آزادی نسبی دارند، اما محدودیتهایی هم دارند. برای مثال، مجوز Llama 3 اجازه استفاده تجاری تا ۷۰۰ میلیون کاربر ماهانه را میدهد و برخی استفادهها را ممنوع میکند. شما یا من میتوانیم با آن چیزی بسازیم، اما شرکتهایی مثل اپل و گوگل نمیتوانند. همینطور سیاستهای محدودکننده استفاده Gemma 2، از جمله ممنوعیت «تشویق یا تسهیل کاربران به انجام هر نوع جرم»، نشاندهنده تمایل گوگل برای جلوگیری از ساخت رباتهای نامناسب «تحت برند Google Gemma» است که خبرساز شوند.
مدلهای زبان بزرگ (LLM) چگونه کار میکنند؟
مدلهای اولیه زبان بزرگ مثل GPT-1 بعد از چند جمله دچار مشکل میشدند و شروع به تولید جملات بیمعنی میکردند، اما مدلهای امروزی مثل GPT-4o قادرند هزاران کلمه را به صورتی تولید کنند که همگی منطقی و قابل فهم باشند.
برای رسیدن به این سطح، LLMها روی مجموعههای بسیار بزرگی از دادهها آموزش دیدهاند. جزئیات آموزش بین مدلهای مختلف کمی متفاوت است—بسته به این که توسعهدهندگان چقدر دقت کردهاند تا حقوق کامل استفاده از منابع را داشته باشند—اما به طور کلی میتوان فرض کرد که این مدلها روی چیزی شبیه کل اینترنت عمومی، تمام کتابها، روزنامهها و مجلات منتشر شده، و حداقل خروجیهای مصنوعی مدلهای قبلی هوش مصنوعی آموزش دیدهاند. به همین دلیل است که LLMها میتوانند متنی با ظاهر بسیار معتبر در موضوعات متنوع تولید کنند.
از این دادههای آموزشی، LLMها میتوانند رابطه بین کلمات مختلف (یا در واقع بخشهایی از کلمات که به آنها توکن گفته میشود) را با استفاده از بردارهای چندبعدی مدلسازی کنند. اینجا است که قضیه بسیار پیچیده و ریاضی میشود، اما اصول اولیه این است که هر توکن شناسهی منحصر به فرد خود را دارد و مفاهیم مشابه کنار هم گروهبندی میشوند. سپس این اطلاعات برای ایجاد یک شبکه عصبی استفاده میشود؛ الگوریتمی چندلایه که بر اساس نحوه کار مغز انسان طراحی شده و در قلب هر LLM قرار دارد.
شبکه عصبی شامل یک لایه ورودی، یک لایه خروجی، و چندین لایه مخفی است که هر کدام شامل چندین گره (نود) هستند. این گرهها تصمیم میگیرند چه کلماتی باید بعد از ورودی بیایند و وزنهای متفاوتی دارند. برای مثال، اگر ورودی شامل کلمه "Apple" باشد، شبکه عصبی باید تصمیم بگیرد که دنبال آن چه بیاید: چیزی مثل "Mac" یا "iPad"، یا "pie" یا "crumble"، یا حتی "by Charli XCX" و یا چیز دیگری. وقتی درباره تعداد پارامترهای یک LLM صحبت میکنیم، در واقع تعداد لایهها و گرههای شبکه عصبی زیرین را مقایسه میکنیم. به طور کلی، هرچه گرهها بیشتر باشد، مدل میتواند متن پیچیدهتر را بهتر درک و تولید کند.
مدلهای چندرسانهای بزرگ (LMM) حتی پیچیدهتر هستند چون باید دادههایی از انواع ورودیهای مختلف مانند تصویر، صدا و ویدیو را نیز در نظر بگیرند، اما معمولاً ساختار و روش آموزش آنها مشابه است.
البته، یک مدل هوش مصنوعی که فقط با دادههای آزاد اینترنت و بدون هیچگونه هدایت خاصی آموزش ببیند، احتمالاً نتایجی غیرقابل کنترل و نامناسب تولید میکند. همچنین احتمالاً خیلی کاربردی نخواهد بود، بنابراین در این مرحله، LLMها تحت آموزشهای تکمیلی و تنظیمات ظریفتری قرار میگیرند تا پاسخهای ایمن و مفیدی تولید کنند. یکی از روشهای اصلی این فرآیند، تنظیم وزنهای ورودی و خروجی گرههای مختلف است، اگرچه جنبههای دیگری هم در این فرآیند وجود دارد.
 1 مایکروسافت لایسنس")
تمام اینها یعنی اینکه اگرچه مدلهای زبان بزرگ (LLMها) مانند جعبههای سیاه به نظر میرسند، اما آنچه درون آنها اتفاق میافتد جادو نیست. وقتی کمی درباره نحوه عملکردشان بفهمید، به راحتی متوجه میشوید چرا در پاسخ به برخی سوالات اینقدر خوب عمل میکنند. همچنین آسان است درک کنیم چرا گاهی اوقات ممکن است اطلاعات بیربط یا ساختگی (که به آن «توهمسازی» یا hallucination گفته میشود) تولید کنند.
مدلهای استدلالی چیستند؟
مدلهای استدلالی مانند OpenAI o3 و DeepSeek R1، مدلهای زبان بزرگی هستند که به منظور تولید پاسخ با استفاده از استدلال زنجیرهای (Chain-of-Thought یا CoT) آموزش دیدهاند.
وقتی به آنها یک سوال داده میشود، به جای پاسخ سریع، مسئله را به چند مرحله ساده تقسیم میکنند و سعی میکنند آنها را مرحله به مرحله حل کنند. اگر با مشکلی مواجه شوند، میتوانند دوباره ارزیابی کنند و از زاویهای متفاوت به مسئله نگاه کنند.
این نوع استدلال به منابع محاسباتی بیشتری نیاز دارد، اما معمولاً به مدلهای هوش مصنوعی قدرتمندتری منجر میشود.
LLMها برای چه کارهایی استفاده میشوند؟
LLMها به دلیل توانایی تعمیمپذیریشان در موقعیتها و کاربردهای مختلف بسیار قدرتمند هستند. همان مدل پایه LLM (گاهی با کمی تنظیم دقیق) میتواند برای انجام دهها کار مختلف به کار گرفته شود. هرچند تمام عملکرد آنها حول تولید متن میچرخد، اما نحوه درخواست و دستور دادن به آنها تعیین میکند چه ویژگیهایی به نمایش گذاشته شود.
در اینجا برخی از کاربردهای رایج LLMها آورده شده است:
چتباتهای چند منظوره (مثل ChatGPT و Google Gemini)
خلاصهسازی نتایج جستجو و اطلاعات دیگر از وب
چتباتهای خدمات مشتری که بر اساس اسناد و دادههای کسبوکار شما آموزش دیدهاند
ترجمه متن از یک زبان به زبان دیگر
تبدیل متن به کد کامپیوتری یا تبدیل یک زبان برنامهنویسی به زبان دیگر
تولید پستهای شبکههای اجتماعی، پستهای وبلاگ و متنهای تبلیغاتی
تحلیل احساسات
نظارت بر محتوا
اصلاح و ویرایش متون
تحلیل دادهها
و صدها کاربرد دیگر. ما هنوز در مراحل ابتدایی انقلاب هوش مصنوعی کنونی هستیم.
اما کارهایی هم وجود دارد که LLMها قادر به انجام آن نیستند ولی مدلهای دیگر هوش مصنوعی میتوانند انجام دهند. چند مثال:
تفسیر تصاویر
تولید تصاویر
تبدیل فایلها بین فرمتهای مختلف
ایجاد نمودار و گراف
انجام عملیات ریاضی و دیگر عملیات منطقی
البته برخی از LLMها و چتباتها ممکن است ظاهراً برخی از این کارها را انجام دهند، اما در بیشتر موارد، یک سرویس هوش مصنوعی دیگر برای کمک وارد عمل میشود — یا در واقع شما از یک مدل چندرسانهای (LMM) استفاده میکنید.
بهترین LLMها
 2 مایکروسافت لایسنس")
GPT-4o
توسعهدهنده: OpenAI
پارامترها: بیش از ۱۷۵ میلیارد
پنجره متن (Context window): ۱۲۸,۰۰۰
دسترسی: API
مدلهای پیشتربیتشده تولیدی (Generative Pre-trained Transformer یا GPT) شرکت OpenAI چرخه هیجان اخیر هوش مصنوعی را آغاز کردند. دو مدل اصلی در حال حاضر موجودند: GPT-4o و GPT-4o mini. هر دو مدل چندرسانهای هستند و میتوانند تصاویر و صوت را نیز پردازش کنند.
تمام نسخههای مختلف GPT مدلهای هوش مصنوعی چند منظوره با API هستند که توسط شرکتهای متنوعی مثل مایکروسافت، Duolingo، Stripe، Descript، Dropbox و Zapier برای ارائه ابزارهای مختلف استفاده میشوند. با این حال، ChatGPT احتمالاً شناختهشدهترین نمایش قدرت این مدلهاست.
o3 و o1
توسعهدهنده: OpenAI
پارامترها: بیش از ۱۷۵ میلیارد
پنجره متن: ۲۰۰,۰۰۰
دسترسی: API
مدل o1 اولین مدل استدلالی OpenAI بود. از زمان عرضه آن، مدلهای استدلالی OpenAI تقریباً همه بنچمارکها و آزمایشهای مستقیم را در اختیار گرفتهاند. تاکنون مدلهای o3، o3-mini، o1، o1-preview و o1-mini عرضه شدهاند.
مانند GPT-4o، مدلهای o1 و o3-mini از طریق API و ChatGPT در دسترساند. خوشبختانه OpenAI متوجه شده که نامگذاری مدلهای مختلف هوش مصنوعی گیجکننده است و نامها سیستم مناسبی ندارند. در آینده، نسخه GPT-5 را منتشر خواهد کرد که مدلهای GPT و استدلالی را در یک خط تولید ترکیب میکند.
Gemini
توسعهدهنده: گوگل
پارامترها: نسخه نانو در دو نسخه ۱.۸ میلیارد و ۳.۲۵ میلیارد؛ سایر نسخهها نامشخص
پنجره متن: تا ۲ میلیون
دسترسی: API
گوگل Gemini خانوادهای از مدلهای هوش مصنوعی گوگل است. مدلهای اصلی—Gemini 2.5 Pro، Gemini 2.5 Flash، Gemini 2.0 Flash، Gemini 1.0 Ultra، Gemini 1.5 Pro، Gemini 1.5 Flash، Gemini 1.0 Nano و Gemini 1.0 Ultra—برای اجرا روی دستگاههای مختلف از گوشیهای هوشمند تا سرورهای اختصاصی طراحی شدهاند و کاربردهای متنوعی را پوشش میدهند.
در حالی که قادر به تولید متن مانند یک LLM هستند، مدلهای Gemini به طور ذاتی توانایی پردازش تصاویر، صوت، ویدیو، کد و سایر انواع اطلاعات را نیز دارند. آنها برای پنجره متنی بلند بهینه شدهاند، یعنی میتوانند حجم زیادی از متن را پردازش کنند.
جدیدترین مدلها همچنین قابلیتهای هوش مصنوعی را در برنامههای گوگل مانند Docs و Gmail تأمین میکنند، همچنین چتبات گوگل که گیجکننده است و آن را هم Gemini مینامند. مدلهای Gemini از طریق Google AI Studio یا Vertex AI در دسترس توسعهدهندگان هستند.
Gemma
توسعهدهنده: گوگل
پارامترها: ۱ میلیارد، ۴ میلیارد، ۱۲ میلیارد و ۲۷ میلیارد
پنجره متن: ۱۲۸,۰۰۰
دسترسی: آزاد
گوگل Gemma خانوادهای از مدلهای هوش مصنوعی آزاد است که بر اساس همان تحقیقات و فناوری توسعه Gemini ساخته شده است. جدیدترین نسخه، Gemma 3، در چهار اندازه مختلف عرضه شده: ۱ میلیارد، ۴ میلیارد، ۱۲ میلیارد و ۲۷ میلیارد پارامتر
Llama
توسعهدهنده: متا
پارامترها: ۱ میلیارد، ۳ میلیارد، ۸ میلیارد، ۱۱ میلیارد، ۷۰ میلیارد، ۹۰ میلیارد و ۴۰۵ میلیارد
پنجره متن: ۱۰ میلیون
دسترسی: آزاد
Llama خانوادهای از مدلهای زبان باز (LLM) متعلق به شرکت متا، مالک فیسبوک و اینستاگرام است. جدیدترین مدلهای Llama 4 (شامل Scout، Maverick و Behemoth [در پیشنمایش]) چندرسانهای هستند و Scout دارای پنجره متنی ۱۰ میلیون است که از هر مدل دیگری در حال حاضر بزرگتر است.
علاوه بر تأمین بیشتر قابلیتهای هوش مصنوعی در اپلیکیشنهای متا، خانواده Llama یکی از محبوبترین و قدرتمندترین خانوادههای LLM باز است و شما میتوانید کد منبع آن را از GitHub دانلود کنید. چون برای پژوهش و استفاده تجاری رایگان است، بسیاری از مدلهای دیگر بر پایه Llama ساخته شدهاند.
R1
توسعهدهنده: DeepSeek
پارامترها: ۶۷۱ میلیارد
پنجره متن: ۱۲۸,۰۰۰
دسترسی: آزاد، چتبات، API
DeepSeek R1 هنگام عرضه سروصدای زیادی به پا کرد. این مدل استدلالیای است که تواناییهایی در حد OpenAI o1 دارد، اما توسط یک شرکت فناوری چینی با سختافزار محدودتر و بودجه بسیار کمتر توسعه یافته و به صورت مدل باز منتشر شده است.
با وجود این موفقیت چشمگیر، تأثیرات کامل نوآوریهای صرفهجویی در محاسبات DeepSeek هنوز به طور کامل درک نشده است. همچنین هنوز مشخص نیست که تحریمهای آینده چه تاثیری بر این شرکت هوش مصنوعی خواهند داشت.
V3
توسعهدهنده: DeepSeek
پارامترها: ۶۷۱ میلیارد
پنجره متن: ۱۲۸,۰۰۰
دسترسی: آزاد، چتبات، API
DeepSeek V3 معادل GPT-4 شرکت DeepSeek است. این یک مدل LLM پیشرفته باز است که قابلیت استدلال یا چندرسانهای ندارد. مانند R1، این مدل با سختافزار محدودتر و بودجه کمتر نسبت به مدلهای معمول LLM توسعه یافته است.
مشابه R1، اگرچه V3 یک دستاورد فنی چشمگیر است، اما هنوز مشخص نیست در یک یا دو سال آینده چقدر محبوب خواهد شد.
Claude
توسعهدهنده: Anthropic
تعداد پارامترها: نامشخص
پنجره متنی (Context window): ۲۰۰٬۰۰۰
دسترسی: API
کلود یکی از رقبای مهم GPT به شمار میرود. سه مدل آن — Claude Sonnet 4، Claude 3.5 Haiku و Claude Opus 4 — به گونهای طراحی شدهاند که کمککننده، صادق، بیضرر و به خصوص امن برای استفاده سازمانها باشند. به همین دلیل شرکتهایی مانند Slack، Notion و Zoom با Anthropic همکاری کردهاند. مدل Claude Opus 4 هماکنون بهترین مدل هوش مصنوعی برای کدنویسی محسوب میشود.
همانند دیگر مدلهای اختصاصی، کلود فقط به صورت API در دسترس است، اما میتوان آن را با دادههای شما آموزش داده و بهینهسازی کرد تا پاسخها مطابق نیازتان باشد.
Command
توسعهدهنده: Cohere
تعداد پارامترها: مدل Command R7B دارای ۷ میلیارد پارامتر است؛ بقیه مدلها نامشخصند
پنجره متنی: تا ۱۲۸٬۰۰۰
دسترسی: API
مدلهای Command شرکت Cohere مشابه Claude 4 برای استفاده سازمانی طراحی شدهاند. مدلهای Command A، Command R7B، Command R و Command R+ از API پشتیبانی میکنند و برای تولید محتوا با بازیابی اطلاعات (RAG) بهینه شدهاند تا سازمانها بتوانند پاسخ دقیق به سوالات کارکنان و مشتریان بدهند.
شرکتهایی مانند Oracle، Accenture، Notion و Salesforce از این مدلها استفاده میکنند.
Nova
توسعهدهنده: آمازون
تعداد پارامترها: نامشخص
پنجره متنی: تا ۱ میلیون
دسترسی: API
آمازون نوا خانوادهای از مدلهای پیشرفته است که روی سرویسهای ابری AWS عرضه میشوند. اگرچه شروع کندی داشت، مدلهای فعلی مانند Amazon Nova Premier، Pro، Lite و Micro در معیارهای مختلف عملکرد رقابتی دارند. با توجه به اهمیت AWS در فضای ابری، احتمالاً این مدلها محبوب خواهند شد.
Mistral
توسعهدهنده: Mistral
تعداد پارامترها: ۱۲۳ میلیارد
پنجره متنی: ۱۲۸٬۰۰۰
دسترسی: وزنهای باز (Open weight)
میسترال یکی از بزرگترین شرکتهای اروپایی هوش مصنوعی است. مدل Mistral Large 2، مدل چندرسانهای Pixtral Large و چتبات Le Chat همگی رقبای مستقیمی برای GPT-4o، Gemini، ChatGPT و سایر ابزارهای پیشرفته هوش مصنوعی هستند.
Mistral Large 2 با وزنهای باز برای مقاصد تحقیقاتی و تجاری عرضه شده است. اگرچه مجوز کاملاً باز نیست، اما میتوان آن را برای کاربردهای خاص آموزش داد.
Qwen
توسعهدهنده: Alibaba Cloud
تعداد پارامترها: ۰.۵ میلیارد، ۱.۵ میلیارد، ۳ میلیارد، ۷ میلیارد، ۱۴ میلیارد، ۳۲ میلیارد، ۷۲ میلیارد، ۲۳۵ میلیارد
پنجره متنی: تا ۱ میلیون
دسترسی: باز، API، چتبات
Qwen خانوادهای از مدلهای هوش مصنوعی شرکت بزرگ چینی علیبابا است. مدلهای مختلفی در خانوادههای Qwen 3 و Qwen 2.5 عرضه شدهاند که شامل مدلهای تخصصی برای دیداری، کدنویسی، ریاضی و پنجره متنی یک میلیونی هستند.
مدل برتر Qwen3 عملکردی برابر یا بهتر از مدلهایی مانند DeepSeek و o1 دارد و در حال حاضر فقط از طریق چتبات Qwen و API در دسترس است.
Phi-3 و Phi-4
توسعهدهنده: مایکروسافت
تعداد پارامترها: ۳.۸ میلیارد، ۷ میلیارد، ۱۴ میلیارد
پنجره متنی: تا ۱۲۸٬۰۰۰
دسترسی: باز
خانواده مدلهای زبان کوچک Phi-3 مایکروسافت برای عملکرد بالا در اندازه کوچک بهینه شدهاند. مدلهای Mini (۳.۸ میلیارد پارامتر)، Small (۷ میلیارد)، Medium (۱۴ میلیارد) و Phi-4 (۱۴.۷ میلیارد) در کارهای زبانی بهتر از مدلهای بزرگتر عمل میکنند.
این مدلها از طریق Azure AI Studio، Hugging Face و دیگر پلتفرمهای مدل باز در دسترس هستند.
Grok
توسعهدهنده: xAI
تعداد پارامترها: نامشخص
پنجره متنی: ۱ میلیون
دسترسی: چتبات و باز
Grok مدل و چتباتی است که بر اساس دادههای شبکه X (توییتر سابق) آموزش دیده است. ابتدا به اندازه کافی شناختهشده نبود، اما Grok 3 اکنون عملکرد و توانایی استدلال پیشرفتهای ارائه میدهد.
با اینکه عملکردش با دیگر مدلها برابری میکند، بیشتر به دلیل اینکه توسط شرکت xAI به رهبری ایلان ماسک توسعه یافته، مشهور است. احتمالاً مدت زیادی در صدر نخواهد ماند اما با توجه به شهرت xAI، ارزش شناختن دارد.
 3 مایکروسافت لایسنس")
چرا این همه مدل زبان بزرگ (LLM) وجود دارد؟
تا چند سال پیش، مدلهای زبان بزرگ محدود به آزمایشگاههای تحقیقاتی و نمایشهای تکنولوژی بودند. اما اکنون این مدلها بسیاری از اپها و چتباتها را راهاندازی کردهاند و صدها مدل مختلف وجود دارد که میتوانید خودتان اجرا کنید (اگر مهارتهای لازم را داشته باشید).
چند دلیل مهم:
با ظهور GPT-3 و ChatGPT، ثابت شد که هوش مصنوعی میتواند ابزارهای کاربردی بسازد و شرکتهای دیگر هم شروع به ساخت چنین مدلهایی کردند.
آموزش LLMها به سختافزار زیادی نیاز دارد اما در چند هفته یا ماه امکانپذیر است.
مدلهای باز زیادی وجود دارد که میتوان آنها را دوباره آموزش داد یا به مدلهای جدید تبدیل کرد بدون نیاز به توسعه کامل از صفر.
سرمایه زیادی وارد حوزه هوش مصنوعی شده و انگیزههای مالی قوی برای توسعه مدلها وجود دارد.
انتظارها از مدلهای زبان بزرگ در آینده
انتظار میرود نوآوری و عرضه مدلهای جدید ادامه داشته باشد. DeepSeek توانست دو مدل پیشرفته را با سختافزار کمتر و بودجه کمتر توسعه دهد. شرکتهای بزرگی مانند اپل، آمازون، IBM، اینتل و NVIDIA هم دلایل خوبی برای توسعه مدلهای خود دارند.
همچنین مدلهای بهینهتر و سبکتری برای دستگاههای موبایل و لبه شبکه خواهیم دید. گوگل این مسیر را با Gemini Nano شروع کرده است و اپل هم هوش مصنوعی خود را برای دستگاههای لبهای به کار گرفته است.
در سالهای اخیر، مدلهای زبان بزرگ (LLM) به یکی از مهمترین فناوریهای هوش مصنوعی تبدیل شدهاند که توانستهاند توانمندیهای بینظیری در درک و تولید زبان طبیعی ارائه دهند. از میان این مدلها، برخی مانند GPT-4 شرکت OpenAI، Claude از Anthropic، و مدلهای Cohere و Mistral به دلیل دقت بالا، انعطافپذیری و امنیت قابل اعتماد، به عنوان بهترین و پرکاربردترین گزینهها در حوزههای مختلف شناخته شدهاند. این مدلها علاوه بر پاسخگویی به سوالات پیچیده، قابلیت انجام وظایف تخصصی مانند کدنویسی، ترجمه، و تحلیل دادهها را با کیفیتی بالا دارند که آنها را برای استفاده در محیطهای تجاری و سازمانی ایدهآل میکند.
یکی از ویژگیهای مهم بهترین مدلهای LLM، توانایی آنها در تطبیق با نیازهای خاص کاربران است؛ به این معنی که میتوان آنها را روی دادههای خاص آموزش داد یا بهینهسازی کرد تا پاسخهایی دقیقتر و متناسب با حوزه کاری ارائه دهند. علاوه بر این، مدلهایی مانند Amazon Nova و Qwen از Alibaba با پنجرههای متنی بسیار گسترده و قابلیت پردازش دادههای چندرسانهای، گامهای بزرگی در افزایش کارایی و کاربردپذیری LLMها برداشتهاند. به طور کلی، این پیشرفتها نشان میدهد که آینده فناوری مدلهای زبان بزرگ با تمرکز بر بهبود عملکرد، افزایش امنیت و کاهش هزینهها، بسیار روشن و امیدوارکننده است.
دیگر مطالب

با وجود فراوانی اپلیکیشنهای کنترل والدین، پیدا کردن گزینهای مناسب برای خانواده میتواند دشوار باشد. با تکیه بر پیشینهام در
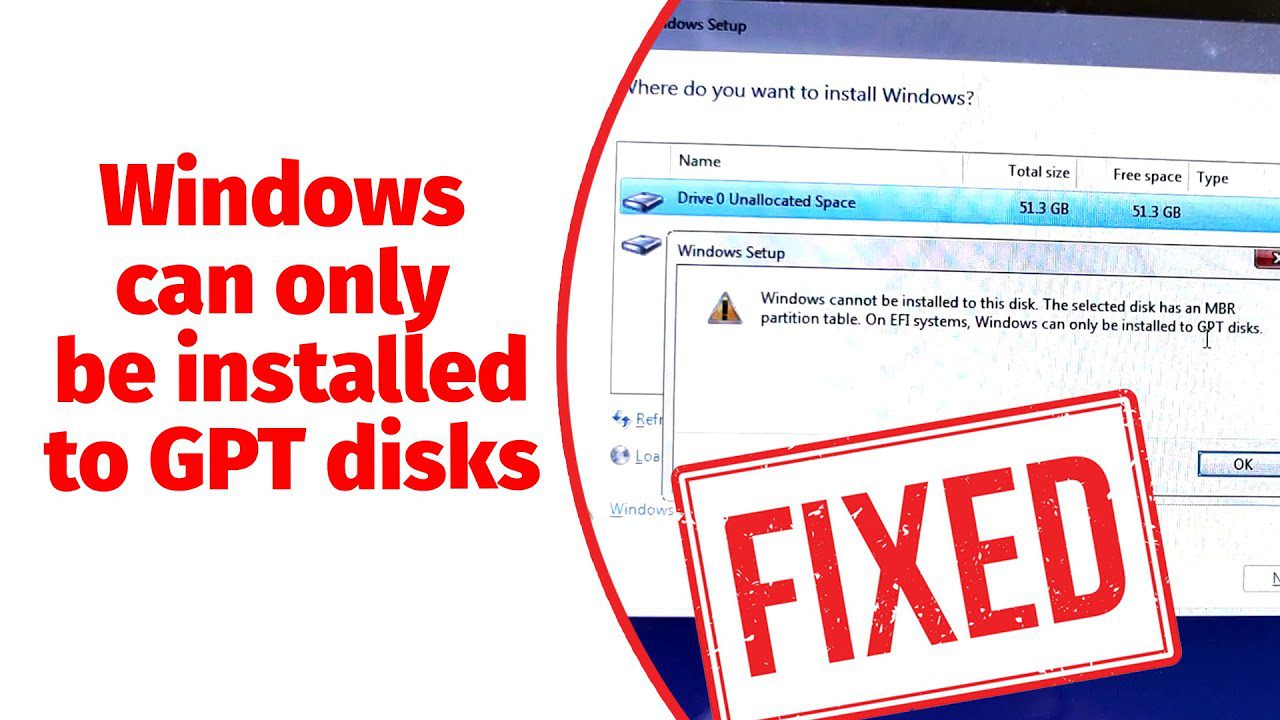
در این مقاله جامع، به بررسی یکی از رایجترین مشکلات هنگام نصب ویندوز 11، یعنی خطاهای مربوط به درایو GPT،
مایکروسافت لایسنس(شرکت رایان نت) به عنوان اولین تأمین کننده رسمی لایسنسهای اصلی محصولات مایکروسافت و تنها همکار تجاری رسمی مایکروسافت در ایران (Microsoft Partner)، با سابقه فعالیت بیش از یک دهه در واردات عمده محصولات اورجینال مایکروسافت و همکاری با بیش از 200 هولدینگ و سازمان دولتی، خصوصی و بینالمللی شاخص و مطرح در ایران و همچنین ارائه خدمات به بیش از پنج هزار مشتری حقیقی و حقوقی، با وجود تحریم های آمریکا، به واسطه شخصیت حقوقی مستقل خود در انگلستان Talee Limited، به عنوان Partner & Solution Provider رسمی مایکروسافت مشغول به فعالیت است. با توجه به حجم موجودی شرکت، تمامی محصولات به صورت فوری تحویل داده میشوند و دارای پشتیبانی، گارانتی و همچنین پشتیبانی فنی مایکروسافت هستند. علاوه بر این، لازم به ذکر است که هیچ یک از محصولات ارائه شده از نوع OEM ،Academic یا Charity نیستند و تمامی محصولات با لایسنس Retail و یا Volume License معتبر و قابل استعلام از مایکروسافت ارائه میشوند. مایکروسافت لایسنس به عنوان یک تأمین کننده رسمی، با فعالیت طولانی در ارائه محصولات اصلی مایکروسافت و تجربه ارائه خدمات به بسیاری از سازمانهای خصوصی و دولتی برجسته کشور، افتخار دارد که تمام محصولات نرمافزاری مایکروسافت را بدون واسطه و با شرایط تحویل آنی و با تضمین بهترین قیمت (بر اساس نوع لایسنس و شرایط استفاده) به صورت مستقیم عرضه نماید.

برخی از مزایای نسخههای اورجینال
افزایش کارایی و سرعت رایانه

پشتیبانی مایکروسافت

امکان دریافت به روز رسانی به صورت واقعی

امنیت بیشتر در مقابل بدافزارها و حملات

پایداری بیشتر در مقایسه با نسخه های جعلی
رعایت قوانین و مقررات

امکان استفاده همیشگی از جواز ویندوز
دریافت نرم افزارهای کاربردی از مایکروسافت که نیاز به ویندوز اصل دارند
بدون نیاز به تعویض های مکرر سیستم عامل نسبت به نمونه کپی

توانایی تشخیص و عیب یابی به وسیله بخش عیب یابی سیستم عامل

مشتریان ما